SymboticMay - August 2024
Software Engineering Internship
Skills Learned: C# and .NET, Visual Studio, Asynchronous Programming, Multithreading, Event-Driven Programming, RabbitMQ and Message Brokering, Git, Windows Forms Applications
During the 2024 summer, I worked as a Software Engineer on the Platform Services team at Symbotic. Symbotic is a warehouse automation company whose product automates the end-to-end workflow of items/packages in a warehouse. The Symbotic system uses robots, conveyor belts and robotic arms to move packages around a warehouse without any need for human labor. Symbotic's most notable customer is Walmart, as the product is currently installed in dozens of distribution centers with a long-term goal of being in all Walmart distribution centers in the coming years.
Platform Services is one of many teams responsible for developing and maintaining the various services and components of the system software. As a member of this team, I spent my summer learning their code, understanding how their services communicate and interact with the rest of the system, and developed a tool to improve my colleagues' ability to find critical content within important log files. This reduced hours of tedious text file searching to mere seconds.
Main Tasks and Responsibilities
- Attend daily scrums and team meetings.
- Understand the system software, dive deep into the code base, step through unit tests to visualize code execution.
- Learn how services communicate through asynchronous messaging (RabbitMQ).
- Understand the event-based interactions between components.
- Develop my summer project.
- Ask questions, interact with my peers (teammates and fellow interns).
- Learn as much as I can about Software Engineering and improve as a computer scientist and problem solver.
Summer Project
One of my team's responsibilities is to manage the asynchronous communication between multiple services within the system software. These services communicate using RabbitMQ, a message brokering software. Message brokers provide a huge advantage as they don't require constant TCP connections where all ends are constantly listening for messages. Instead, a sending service can post a message to a queue and the receiving service can read from that queue whenever it's ready. The message broker can also ensure reliable data transfer and eliminate bit error or packet loss. Oftentimes, components within these services fire events to tell other components to perform actions, and the result of this action is sent in a message via RabbitMQ to another service.
Each time messages are sent or received by a service, that service will record the message to a log file. Bring together dozens of services that send thousands of messages a minute and these log files quickly start to baloon in size. Oftentimes, Platform Services needs to go into these logs to find and diagnose issues. Due to the size and density of the log files, this can take hours by hand. Therefore, I was tasked with creating an application that would assist our team with this process.
The goals of my application were to:
- Sort and organize logs based on their log type.
- Filter out unneccessary information.
- Reformat logs into easy-to-read sentences.
My tool implements these features through two components: the Grepper and the Tracker. The Grepper is responsible for parsing log lines into log types (explained below), filtering logs based on their type or keywords/phrases present in the log line, and sorting logs into specific files based on their type. The Tracker then uses the output of the Grepper to generate reports for specified packages and/or locations within the system that detail all the movements, events, and actions that took place in chronological order.
Log Types
A log type is a class that represents a specific log line in memory. The first goal of the Grepper is to read in log lines, determine if they are of a known type, and then parse that line into the appropriate object based on the data contained within the string. Lets say, for example, we have a log that indicates that a package was moved. The raw log line may look something like this:
2024-08-12 12:34:00 Message Published: PackageMoved, SourceLocation: ABC, DestinationLocation: DEF, ID: 123456
The log type for this log line would look something like this:
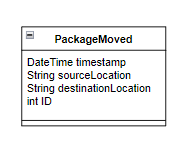
When the Grepper comes across a log line that contains "Message Published: PackageMoved", it will identify the log line as a PackageMoved log and call on the appropriate function to parse the log into a PackageMoved object. Log types therefore allow the Grepper to store logs in memory and identify them by their type.
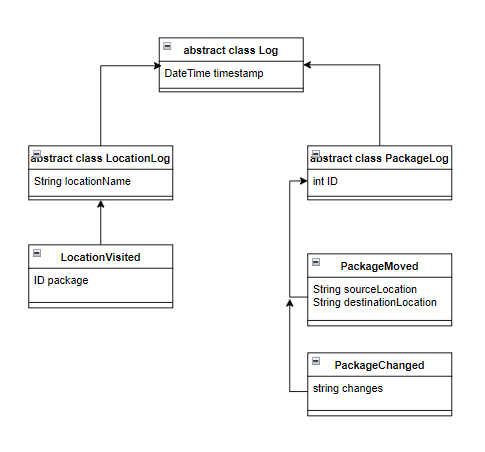
Extension and abstract classes are used to categorize logs and save code. All log types extend a parent abstract class called "Log", which contains common fields that all log lines have, such as a timestamp. Then, other abstract classes like "PackageLog" or "LocationLog" have common fields of logs that pertain to a package or location. Specific logs that belong to these general categories then extend these classes. This creates an extension tree that categorizes the log types and provides access to common fields through the parent classes. A simple example of this structure can be seen below:
Filtering by Phrase
One of the features of the Grepper is the ability for the user to filter a log based on any keywords or phrases that are present in the line. For example, lets look at a set of logs that detail a game of fetch between myself and my dog Lenny.
Harrison lets Lenny out of the cage.
Lenny sprints outside after Harrison opens the door.
Harrison throws the ball.
Lenny chases the ball.
Lenny catches the ball and brings it back to Harrison.
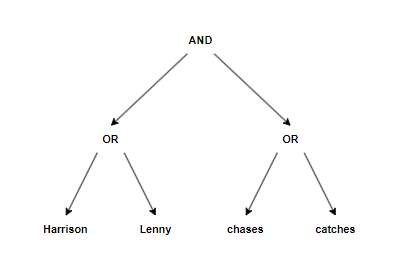
At runtime, the user supplies a boolean statement that details which phrases should be present in the line. They supply the following statement:
(Harrison or Lenny) and (catches or chases)
In english, this statement translates to: The log line must contain the phrases "Harrison" OR "Lenny" AND contain the phrases "catches" OR "chases".
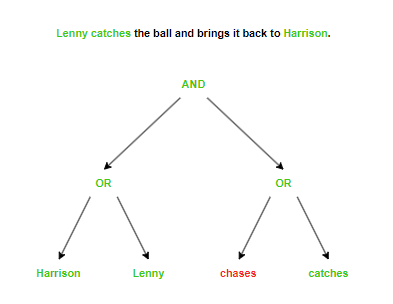
This results in the following lines being included or dropped.
Harrison lets Lenny out of the cage.
Lenny sprints outside after Harrison opens the door.
Harrison throws the ball.
Lenny chases the ball.
Lenny catches the ball and brings it back to Harrison.
The Grepper implements this feature by taking the boolean statement provided by the user and transforming it into a binary tree:
Now that the tree holds the boolean logic to filter a log, all the Grepper has to do is figure out which phrases are present or not present in the log line and subsequentially compute the tree for a result.
Asynchronous Parsing (Flawed Design)
One of my design goals for the tool was strong extendability: I wanted it to be really easy to add new log types without having to change any of the parsing code. Ideally, all a user would have to do is add a new class for the type and implement a static method that could take a raw log line and parse it into that specific object. Therefore, I arrived upon my first parsing design:
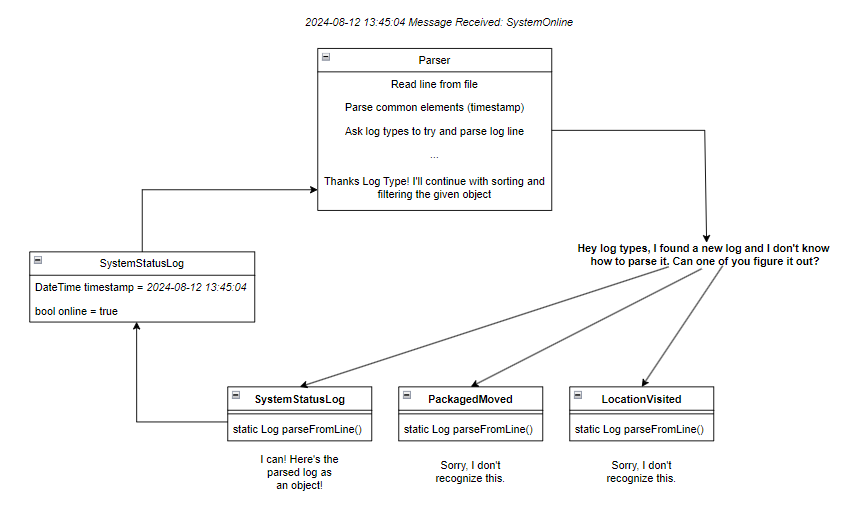
There are two key details to mention here. First, the parser does not actually know which log types exist in the system. All it knows are which objects extend the abstract class Log, allowing it to query all the classes that extend Log and then later call on their methods. When it comes time for the parser to tell the log types to parse a raw log line, it does so by calling the static parseFromLine() method, which returns a Log object. This brings me to the second key detail. These methods execute in their own threads (using C# tasking) asynchronously. This allows all the log types to parse simultaneously, keeping the algorithm efficient.
However, this initial design led to huge performance issues. With only a few log types in the tool, it was taking minutes to parse only a few thousand log lines. Upon closer analysis, I realized there was a fundamental flaw to this algorithm: the time complexity was polynomial. Each time a log line needs to be parsed, new tasks/threads have must be created for each log type. Therefore, O(n) = N x L, where N is the number of log lines to parse, and L is the number of log types. As N or L increases, the time to parse all log lines increases exponentially.
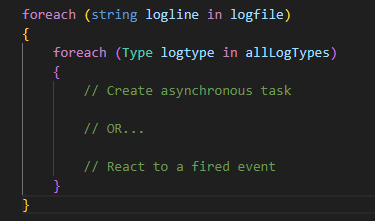
One idea I had to solve this problem was to run simultaneous parsers for each log type in entirely separate true threads (forego C# tasking). This would require the threads to read from the same file simultaneously. However, I found out that the operating system can only allow one thread to read from a resource at a time. Therefore, the threads would have to queue for each log line, bringing me back to the same problem as before.
After I realized this fundamental flaw, I switched gears to a different approach. The parser is now also responsible for identifying the log type. Once it knows which log type a log line belongs to, it then calls on the correct class to parse the log line. Unfortunately, this meant that the original extendability was lost. Each time a log type is created, not only does the developer have to write a new class, they also have to add logic to the parser in order for it to be able to identify the new log type from its raw log line.
Coming to this conclusion was the most challenging, rewarding, and interesting moment of my summer internship. I spent hours trying to figure out this efficiency problem, trying numerous different ideas to work around the speed drops. Through my efforts, I absorbed a plethora of information surrounding mutlithreading, C# tasking, file reading, event-based programming, string-aliasing, and more. While I was unfortunately unable to preserve the extendability of the tool, I learned a valuable lesson about understand algorithm time complexity and the trade-offs computer scientists often have to make when developing their code.
Generating Reports
The Tracker, the component responsible for generating easy-to-read reports that detail what happened within a log set chronologically, uses the Grepper to parse and filter down the log set into objects that are relevant to the items that the Tracker is making a report for. Once it obtains this list of logs from the Grepper, it sorts the logs by their timestamp and subsequentially iterates through the objects. When it comes across a log type that it cares about, it calls upon a helper function responsible for taking that log line and transforming it into a readable sentence that highlights the important information in the line. After completing the iteration, the tracker then formats these sentences and produces a report detailing the actions that occurred within the log set.
Results
Using the tool, the user can now sift through millions of log lines in a matter of seconds to find the specific information they desire. Using just the grepper, they can sort all logs into files based on their type and filter logs based on their type or keyword. Using the tracker, they can generate easy-to-read reports that tells them everything they need to know about the relevant actions and events that took place within the log set. With this tool, the user can eliminate hours of tedious file grepping down to mere seconds, allowing them to spend more time identifying the actual problems from the information the Tracker has given them.
Overall Experience
The reason I decided to pursue an internship for the 2024 summer was to learn what it was like to work as a Software Engineer. I wanted to understand the job, experience the day-to-day lifestyle, and see if it was a career I would enjoy in the future. I am glad to say that my experience with Symbotic makes me excited for my future as a computer scientist. I loved the work, the people, and the problems I got to tackle each day. I learned invaluable lessons that have forwarded my career development, and I cannot wait to see what my future will hold.
I would like to say a big thanks to my manager, Michael Palone, for his continued support and mentorship throughout the summer. Additionally, I could not have achieved what I did without help from the rest of the Platform Services team, especially James Harris and Fred Boucher. Finally, I also want to say thank you to my fellow interns whom I had the pleasure of working alongside, and to Jena Hook for organizing amazing intern events and meetups throughout the summer.