Northeastern UniversityNovember - December 2024
Filesystem
Skills Learned: C, Linux, WSL, FUSE, Operating System API, Low Level Programming
Code Available Upon RequestA filesystem is an essential component of any computer. Filesystems allow machines to manage the organization, storage, and retrieval of information on hard drives. Without this service it would be impossible for computers to manage their digital data. To learn more about a filesystem's structure, implementation, and communication with the operating system, I built a simple filesystem in C to manage a virtual 1MB hard drive.
System Specifications
This filesystem was built with the following specifications. These were mainly chosen for simplicity and compatibility.
- Operating System: Linux
- Max File Size: 4KB (4096 bytes)
- Max Files in a Directory: 60
- Max File Name Length: 64 characters
On launch, the virtual hard drive is mounted within WSL (Windows Subsystem for Linux) while the filesystem is initialized to communicate with linux system calls using the FUSE library. This allows the filesystem to run in user space, avoiding direct access to the kernel (explained below).
FUSE (File System in Userspace)
FUSE is a software interface that allows developers to create custom filesystems without needing to access/modify UNIX kernel programs. The library creates bridges between system calls to functions (implemented by the developer) that can run in userspace like a normal program. This makes it easy for someone to create and run their own filesystem without having to worry about accessing the kernel, leading to potential conflicts with their operating system. Because of these advantages, I leveraged FUSE to mount my filesystem within the kernel and configure my program to respond to actual linux commands such as cd (change directory), ls (list), echo, and more. This allows the user to interact with my filesystem from the defualt linux shell just like any other storage drive on the machine. With this setup, my entire implementation is built to implement the FUSE interface, allowing my program to run in it's own process and communicate solely with FUSE in the kernel.
More information on FUSE can be found here.
Overall Structure
The general structure for my filesystem closely aligns with the basic layout of a typical UNIX filesystem. In UNIX filesystems, the disc (hard drive) is separated into relatively small blocks, translating the disc into an array of storage locations. The first few blocks are reserved to store metadata about the files on the disc, whereas the rest of the blocks (data blocks) store the actual data within the files. In my filesystem, each block is around 4KB (4096 bytes) in size resulting in 256 blocks throughout the entire 1MB (1,058,576 bytes) virtual disc. To keep things simple, each file in my filesystem takes up one and only one data block. This makes it easy to map data blocks to files, however the downside is that the max file size is restricted to the size of a block (4096 bytes).
The metadata for each file is stored in an inode object. An inode is a struct that holds important information about a file. This includes the file's type, size, permissions, links, and data block number. Every file must have an inode, as these structures are used to organize the data on disc. The inode struct used in my filesystem can be seen below:
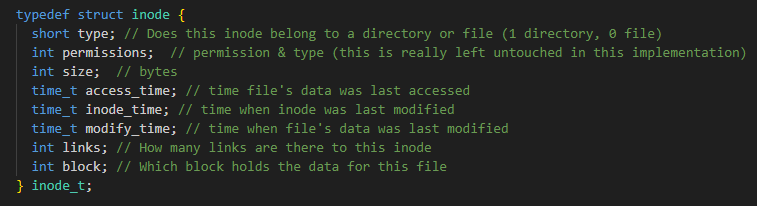
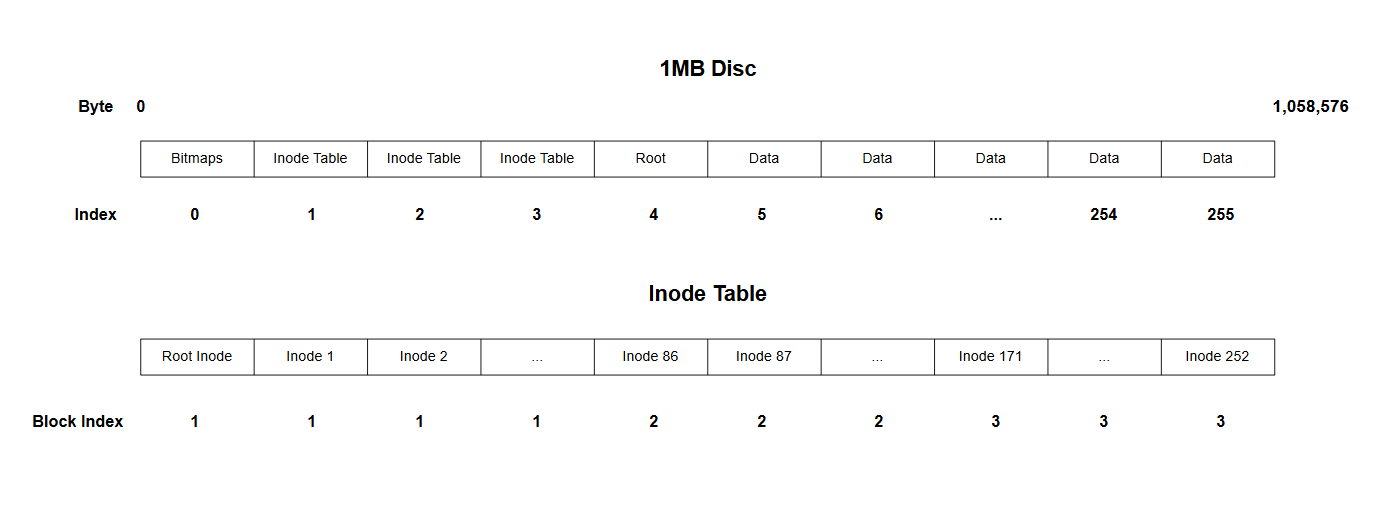
Generally, the first block within a disc is reserved for the superblock. This normally contains general information about the disc such as the type of filesystem, how much storage is available, and how to initialize (mount) the disc with the operating system. Because my filesystem only manages a virtual disc, most of this information is irrelevant, and thus for simplicity my filesystem does not contain a superblock.
Instead, the first block in my filesystem stores the data block bitmap and the inode bitmap. Bitmaps are useful for tracking the binary states. In this case, I use bitmaps to store the availability of the data blocks and inodes in the filesystem by mapping each object's availability to a binary number (0 for free, 1 for in use). Thus, we can keep track of all the available data blocks and inodes using two 64 byte (256 bit) bitmaps. Technically, the inode bitmap can be slightly smaller than 256 bits since inodes aren't needed for the first few metadata blocks, but for simplicity it's easier to keep both bitmaps the same length.
Blocks 2, 3, and 4 store the inode table. The inode table holds all the inodes that could possibly be needed for all files in the system, meaning there needs to be one inode per data block. The total size of my inode struct is 48 bytes. Given 252 data blocks, we need 12,096 bytes to store all the inodes (total space in 3 blocks = 4096 (block size) * 3 = 12,288). Therefore, three blocks are allocated for the inode table. With this setup, only simple memory address shifts/arithmetic is needed to obtain the desired inode struct, making this operation very efficient (constant lookup).
The rest of the blocks (5-256) are data blocks, with the first data block holding the root directory. Data blocks store information for both directories and normal files. On creation, each file is allocated an inode and a data block, with the file's inode storing the block number. When the filesystem needs to obtain the data in a file, it will search for that file's inode by starting at the root directory, obtain the block number, and then return the starting address of the data block (explained further below).
Filesystem Structure
Files and Directories
In my filesystem, there are two types of files: normal files and directories. Directories are special files which "contain" other files (both normal files and other directories). Aside from the root, all files must exist in some directory. This structure is similar to a tree, where directories are nodes and normal files are leafs. All files have a path to root, and any file can be reached from traversing the tree from the root node. In a directory file's data block, a struct keeps track of the directory's size, number of contained files, the directory's inode, and the directory's parent inode. It also contains a list of the sub files present in the directory. This list is really a mapping between the name of each file name and it's corresponding inode. To keep the size of each entry consistent, a filename's max size is capped at 64 characters. To fully fit the 4096 byte data block, there can be at most 60 files in the directory. Thus, the maximum number of files in a directory is capped at 60.
Directory Struct
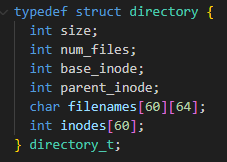
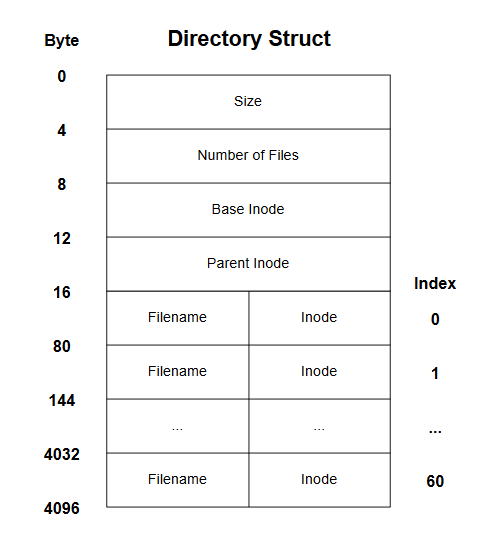
Each filename to inode mapping is referred to as a hard link. An inode can be linked to many different filenames, meaning the data in a file can technically be saved in many different directories under multiple names. The number of links to an inode is saved in the inode struct. For normal files this is a helpful feature, however issues arise when directores have multiple links. Therefore, the system only allows hard links to be created for non-directory files. Furthermore, the user can also "unlink" a file by removing a specific filename to inode mapping in a directory. If unlinking a file results in an inode having zero links, the file is considered deleted. When this scenario occurs in my filesystem, the file's inode and data block are subsequently freed (mutating the bitmaps), thus allowing these resources to be used for new files.
Using the Filesystem
The filesystem is tied together by implementing the FUSE interface in terms of method calls to the structures explained above. These FUSE interface methods act as handlers that are directly connected to corresponding read, write, and stat requests in the kernel. For example, when the operating system wants to obtain the metadata for a file, it will make a "stat" request. With FUSE, this request is relayed directly to the handler method in my filesystem's implementation, which will find the inode corresponding to the given filepath. Finally, the method will complete the stat request by returning the metadata present in the inode, or return an error code if something went wrong.
All of the FUSE handlers are implemented in a similar pattern. First, the given filepath is used to obtain an inode. Next, the file's data block is obtained from the inode's block field. Depending on the method, the information in the data block is then read or overwritten with new information. Finally, once the desired actions have taken place, the relevant inodes, directories, and bitmaps are appropriately mutated to reflect the changes to the filesystem.
Overall, this setup makes it easy for the user to interact with my filesystem. Once mounted, the user can navigate through the virtual disc just like they would with the default filesystem on their machine. They can navigate to any directory, view the files in a directory, create files, modify files, and delete files. They can create hard links, move files, and request file metadata. Importantly, each time the user makes a request, FUSE calls on our implementation for a response. This response correctly handles the request by interacting with our custom structures.
Overall Experience
My favorite part of creating this filesystem was exposing myself to low level programming using C. Most of my software experience has involved high level, object-oriented programming that hides away most of the underlying technical details that occur within a computer. This project forced me to learn how to closely interact with an operating system, manage memory approriately, program with very few safe guards, and understand every minute detail of my codebase. I spent hours investigating segmentation faults, shifting memory addresses, manipulating pointers, and performing binary operatins on bytes of memory. Through hard work, I learned invaluable lessons about the inner-workings of modern day computers.
I also enjoyed getting the opportunity to learn Linux. I had briefly worked with a few Linux machines in past projects, however I never had the opportunity to interact with the operating system in a non-trivial fashion. I learned about Linux's basic structure, the responsibilities the operating system has within a machine, how Linux interacts with the CPU, and much more.
Overall, this project was a fresh experience that differed greatly from my previous work. I have picked up many new skills and a newfound understanding of computers through designing this filesystem, and I'm excited to build upon this knowledge with future projects and experiences.